visualiser la divergence entre l’IPC et la consommation en biens
Dans ce court article, nous allons regarder comment produire un graphique permettant de comparer l’évolution des prix de la consommation alimentaire et l’évolution des quantités de biens consommés. Pour cela, nous allons utiliser les données de l’INSEE ainsi que pandas et matplotlib.
Un graphique similaire a tourné sur Twitter avant d’atterrir sur Mastodon. Intrigué par son petit côté spectaculaire, il semble important de pouvoir le déconstruire et le reconstruire au moins pour canaliser un biais de confirmation.
Un peu d’autodéfense statistique ne fait jamais de mal.
les données
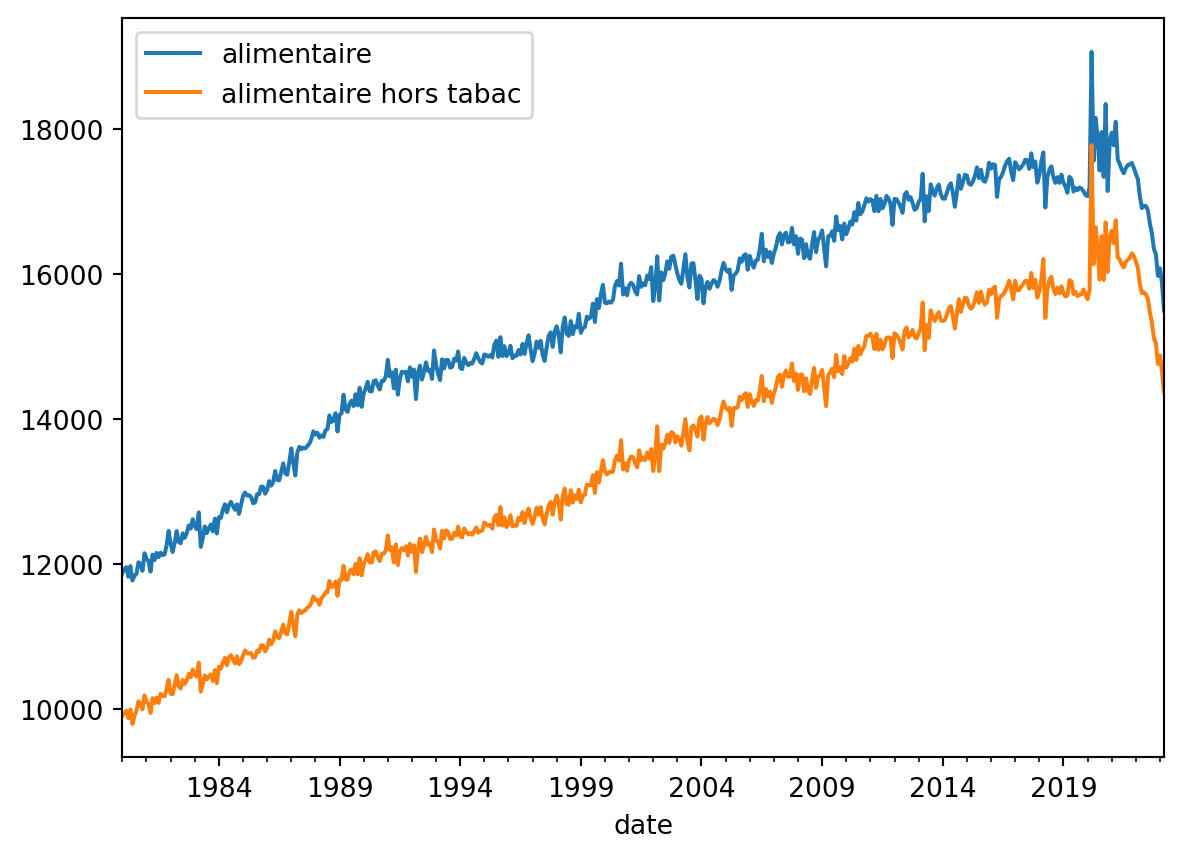
la consommation des ménages en biens
Les données proviennent de l’INSEE dans le cadre d’un suivi régulier des dépenses de consommation. Le fichier mis à disposition est un fichier Excel assez sale, mais facile à remettre en forme en quelques lignes de pandas. La principale fonction est pd.read_excel() qui sait aller chercher tout seul un fichier derrière une URL. Avec quelques paramètres pour notamment sauter des lignes de présentation ainsi que sélectionner directement quelques colonnes, on a assez rapidement un beau pd.DataFrame.
l’indice des prix à la consommation
L’indice des prix à la consommation fait également partie d’un suivi régulier par l’INSEE.
Pour l’indice des prix à la consommation c’est la même manipulation, mais cette fois-ci, les données sont fournies dans un zip. Il faut donc aller le dézipper au préalable ; ce que ne sait pas faire pandas. C’est très certainement automatisable, mais pour cet exemple, j’ai fait cela à la main.
La série est en base 100 en indice 2015. Ce qui signifie que les valeurs sont à interpréter comme un taux de variation multiplié par 100. Ce ne sont pas donc pas des valeurs absolues comme des euros ou des tonnes. L’intention est de donner une lecture centrée sur l’évolution des ordres de grandeur.
À noter aussi l’usage de pd.to_datetime() pour convertir la colonne date en objet datetime de pandas.
Définition : l’indice des prix à la consommation harmonisé (IPCH) est utilisé pour les comparaisons entre membres de l’Union européenne. Il est calculé pour tous les ménages, en France. La principale différence entre l’IPCH et l’IPC porte sur les dépenses de santé : l’IPCH suit des prix nets des remboursements de la sécurité sociale tandis que l’IPC suit des prix bruts.
https://www.insee.fr/fr/statistiques/7233968#tableau-ipc-flash-g1-fr
# HICP - Reference year 2015=100 - All households - France - COICOP
# classification: 01 - Food and non-alcoholic beverages Identifier 001762445
ipc = (
pd.
read_excel(
'data/serie_001762445_05072023.xlsx',
skiprows = 3,
names = ['date', 'ipc']
)
.assign(date = lambda df: pd.to_datetime(df.date))
.set_index('date')
.sort_index()
)
(
ipc
.plot
.line()
);/home/tk/.virtualenvs/kitchen/lib/python3.10/site-packages/openpyxl/styles/stylesheet.py:226: UserWarning: Workbook contains no default style, apply openpyxl's default
warn("Workbook contains no default style, apply openpyxl's default")
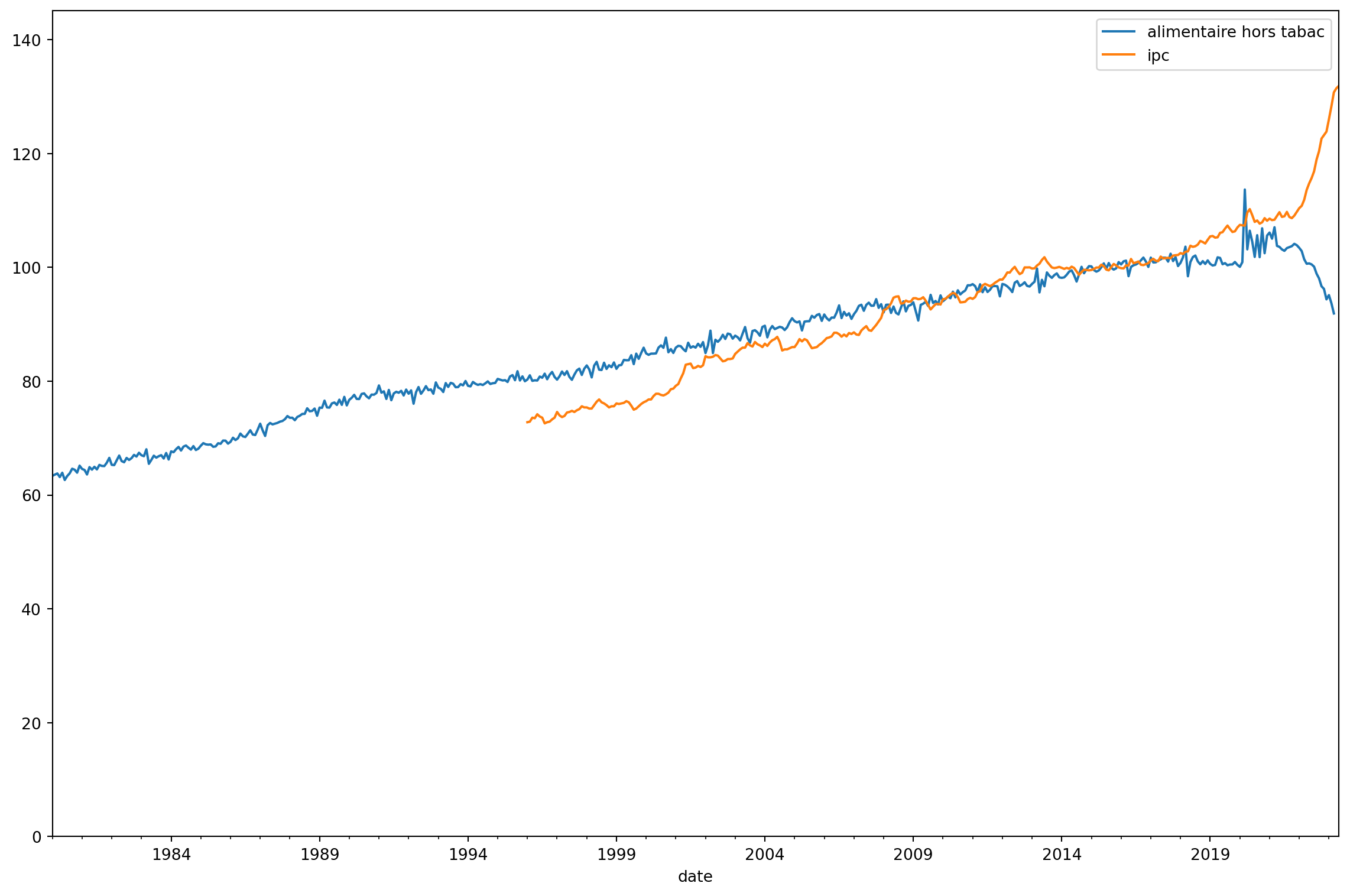
les deux courbes affichées sans aucun pré-réglage
Code
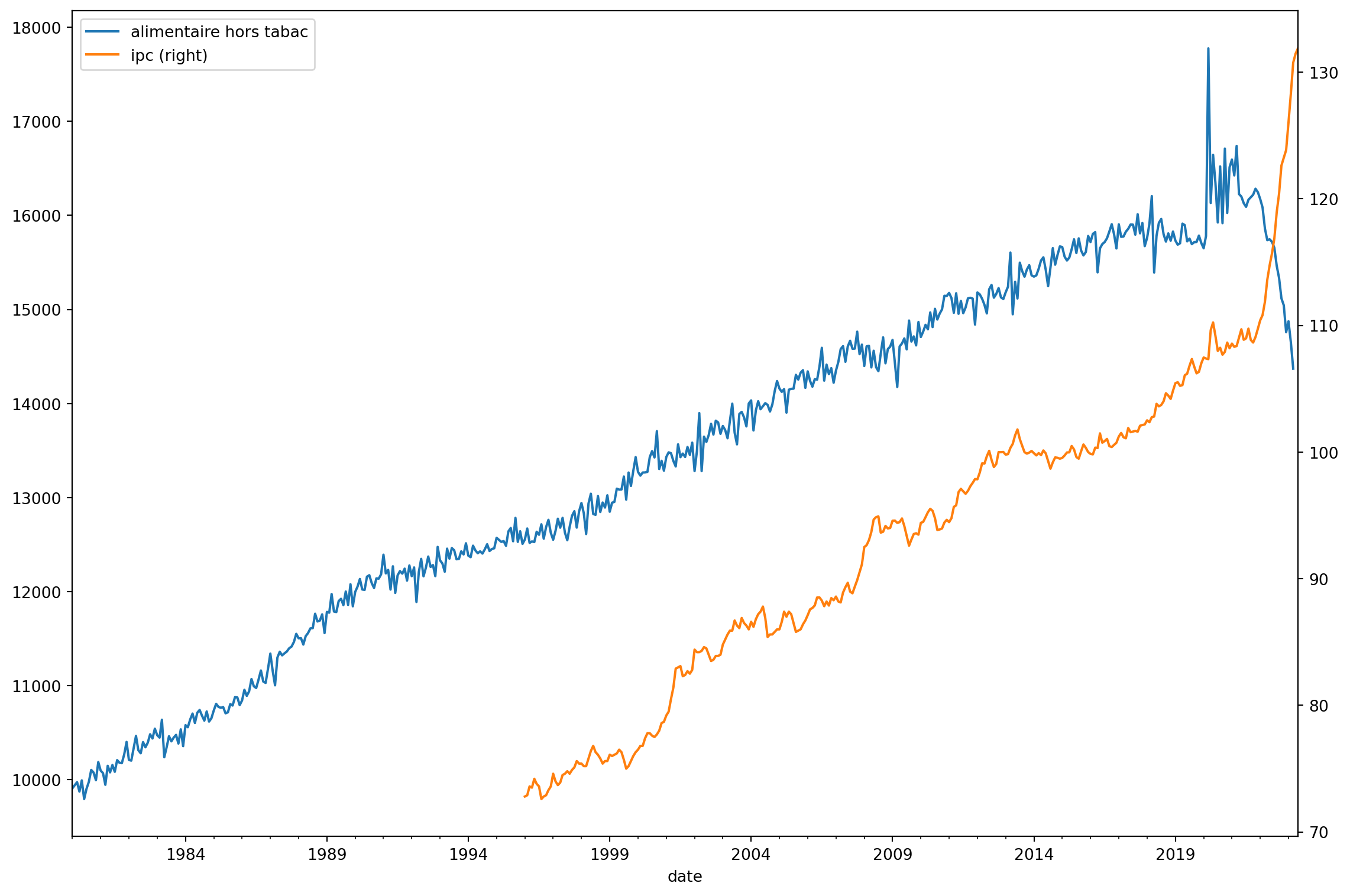
Ceci est l’affichage brut des deux séries chacune avec une échelle différente ainsi qu’une pronfondeur temporelle différente.
consommation en biens indexée sur 2015
Pour commencer à comparer les deux séries, on va les ramener à une base commune : la base 100 indexée sur 2015. Pour cela, rien de plus simple, on récupère la moyenne de l’ipc en 2015, on divise le reste de la série par cette valeur (.div()) et on multiplie par 100 (.mul(100)).
Code
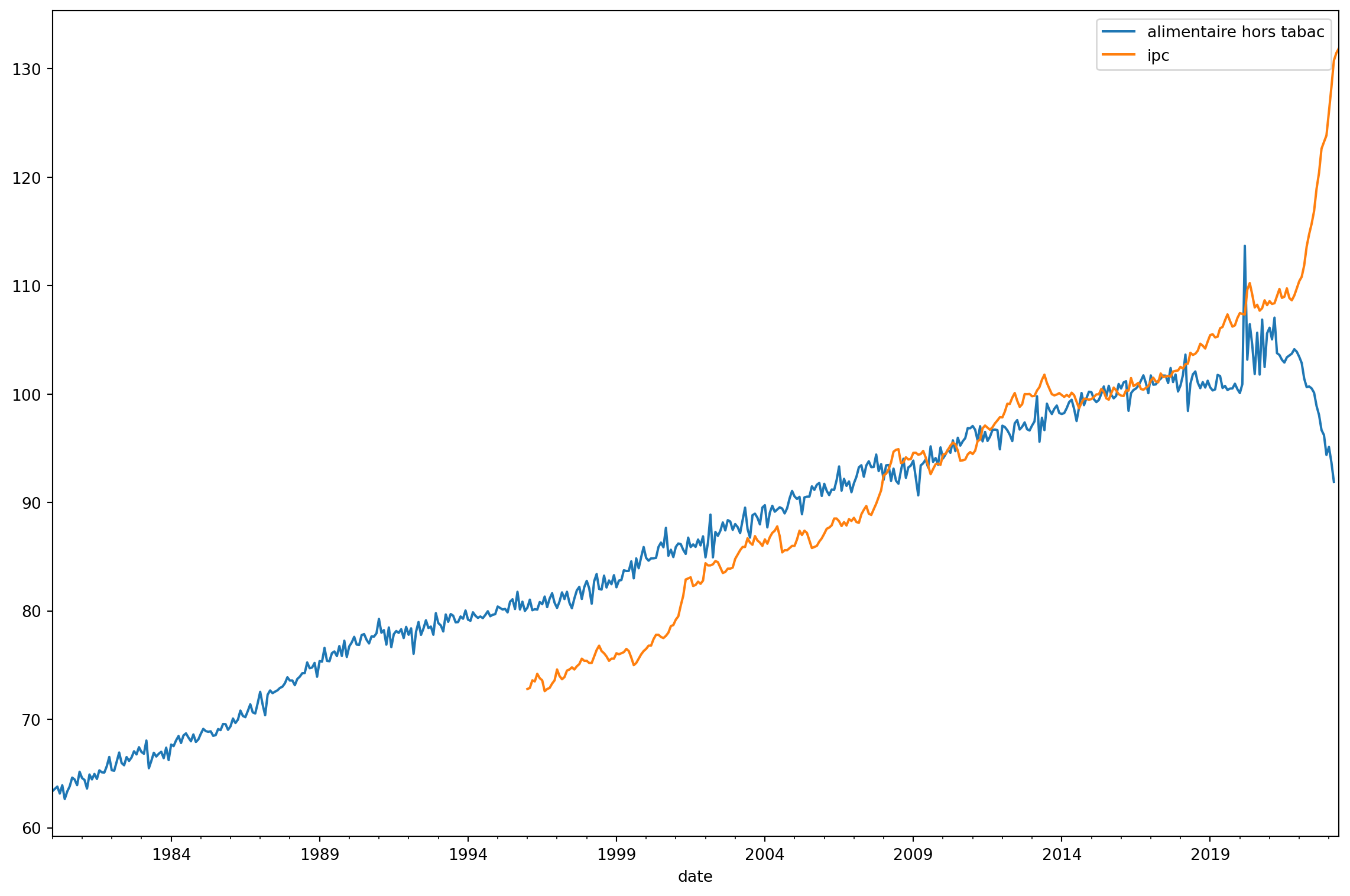
Ce graphique commence à ressembler au graphique initial. Il est intentionnellement centré sur 2015 au niveau de l’abscisse ce qui évacue l’effet de hasard des superpositions de graphiques à double échelle.
une abscisse qui commence à 0
La divergence est assez prononcé mais par acquis de conscience, cela ne fait pas de mal de voir à quoi ressemble le graphique quand on force la présence d’une origine avec la méthode .set_ylim() de matplotlib.
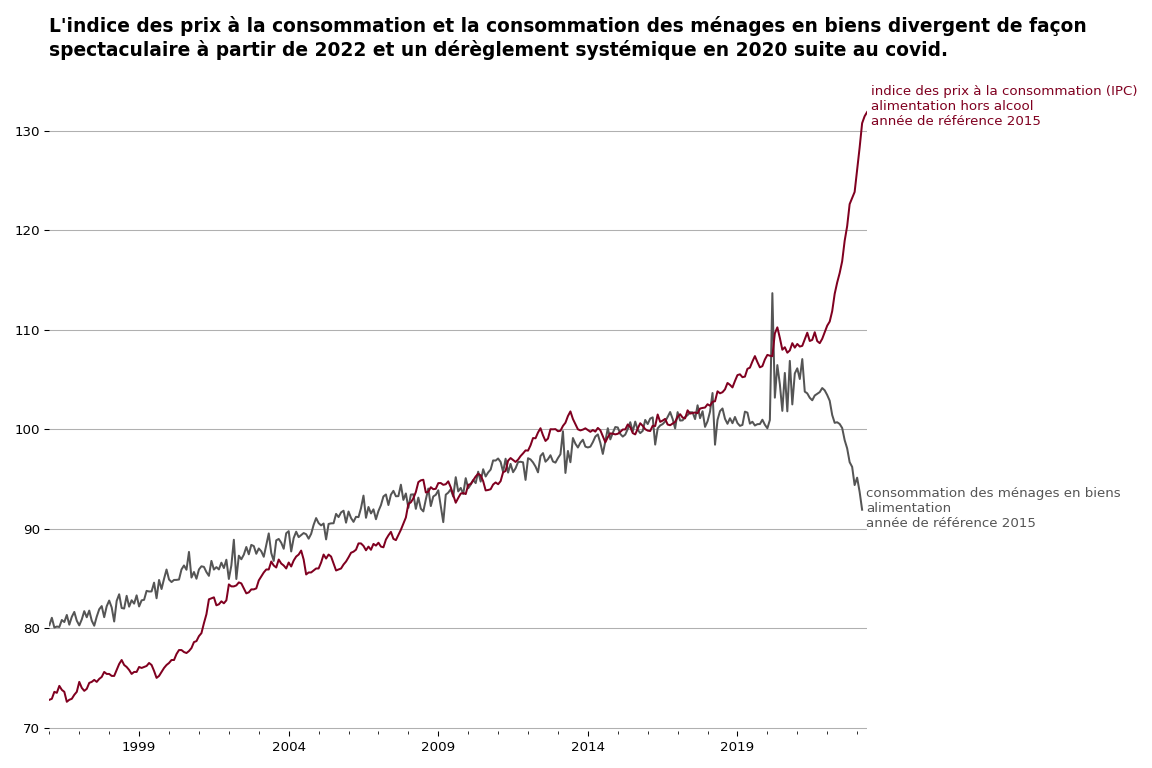
avec un peu de travail cosmétique
Maintenant pour rendre le graphique présentable, nous allons appliquer les principes suivants :
- enlever le cadre du graphique pour réduire le bruit visuel ;
- utiliser une grille horizontale pour faciliter la lecture des valeurs ;
- remplacer la légende par une annotation de chacune des séries pour éviter la répétition de l’information ;
- et enfin mettre un titre descriptif pour guider la lecture.
fig, ax = plt.subplots(figsize=(12,8))
(
biens_2015
.loc['1996':]
.plot
.line(
ax= ax,
y = 'alimentaire hors tabac',
color = '#555'
)
)
ax.annotate(
text = 'consommation des ménages en biens\nalimentation\nannée de référence 2015',
xy = (biens_2015.index[-1], biens_2015['alimentaire'].iloc[-1]),
xytext = (3, 6),
textcoords = 'offset points',
color = '#555'
)
(
ipc
.plot
.line(
ax = ax,
color= '#800020'
)
)
ax.annotate(
text = 'indice des prix à la consommation (IPC)\nalimentation hors alcool\nannée de référence 2015',
xy = (ipc.index[-1], ipc.ipc.iloc[-1]),
xytext = (3, -10),
textcoords = 'offset points',
color= '#800020'
)
ax.get_legend().remove()
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.set_xlabel(None)
ax.grid(axis='y')
ax.set_title("""
L'indice des prix à la consommation et la consommation des ménages en biens divergent de façon spectaculaire à partir de 2022 et un dérèglement systémique en 2020 suite au covid.
""",
loc = 'left',
fontdict = {
'fontsize': 14,
'fontweight': 'bold'
},
wrap = True
)
plt.tight_layout()
plt.savefig('graphics/divergence_ipc_consobiens.png')
plt.show()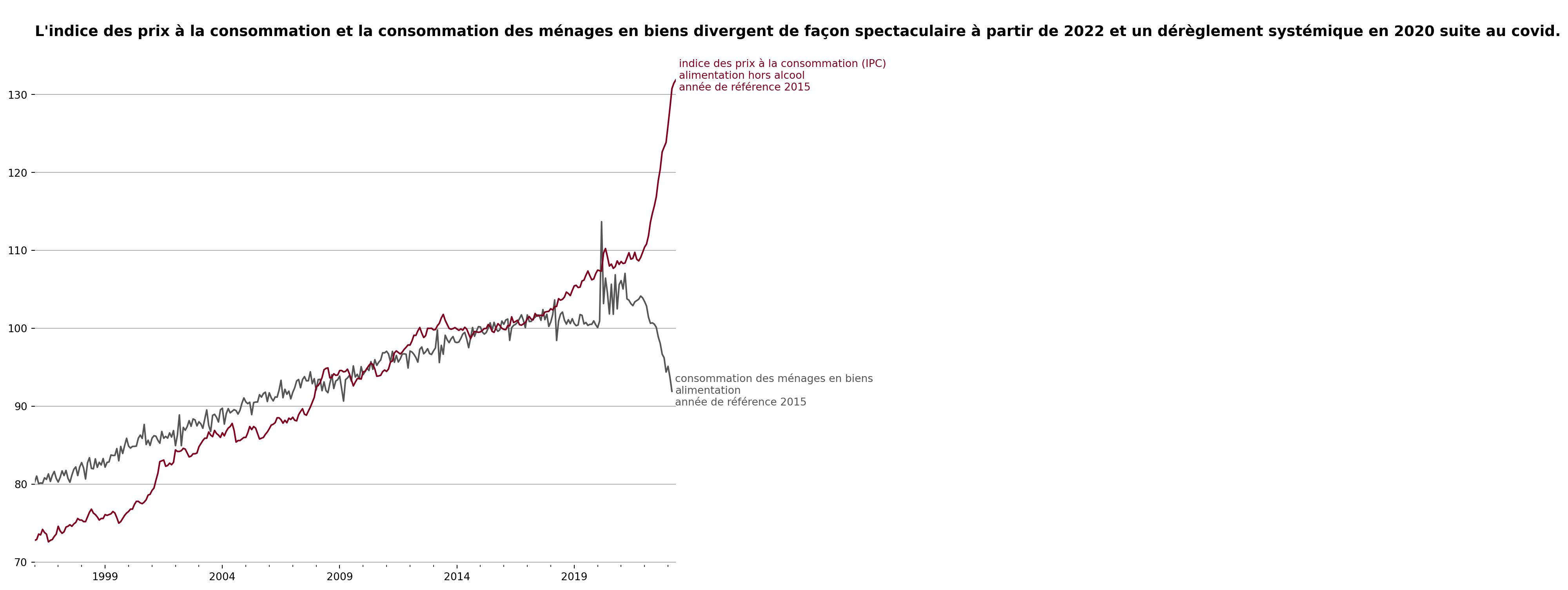
compilation des données
Pour finir, il faut exporter les données pour éventuellement les utiliser dans un autre logiciel de visualisation.