spatialisation des députés avec une analyse en composantes principales
Dans le cadre d’un article sur l’anniversaire de la 16e législature et au détour d’analyses sur les votes et les interventions des députés, j’ai pu produire une modeste spatialisation des députés en fonction de leur vote. Cet article est une recette assez simple pour reproduire cette visualisation en expliquant les différentes étapes ainsi que les principes rationnels en arrière-fond. Ce n’est pas vraiment de la cuisine de haute volée, mais de la transparence sur les méthodes ne fait jamais de mal.
la visualisation
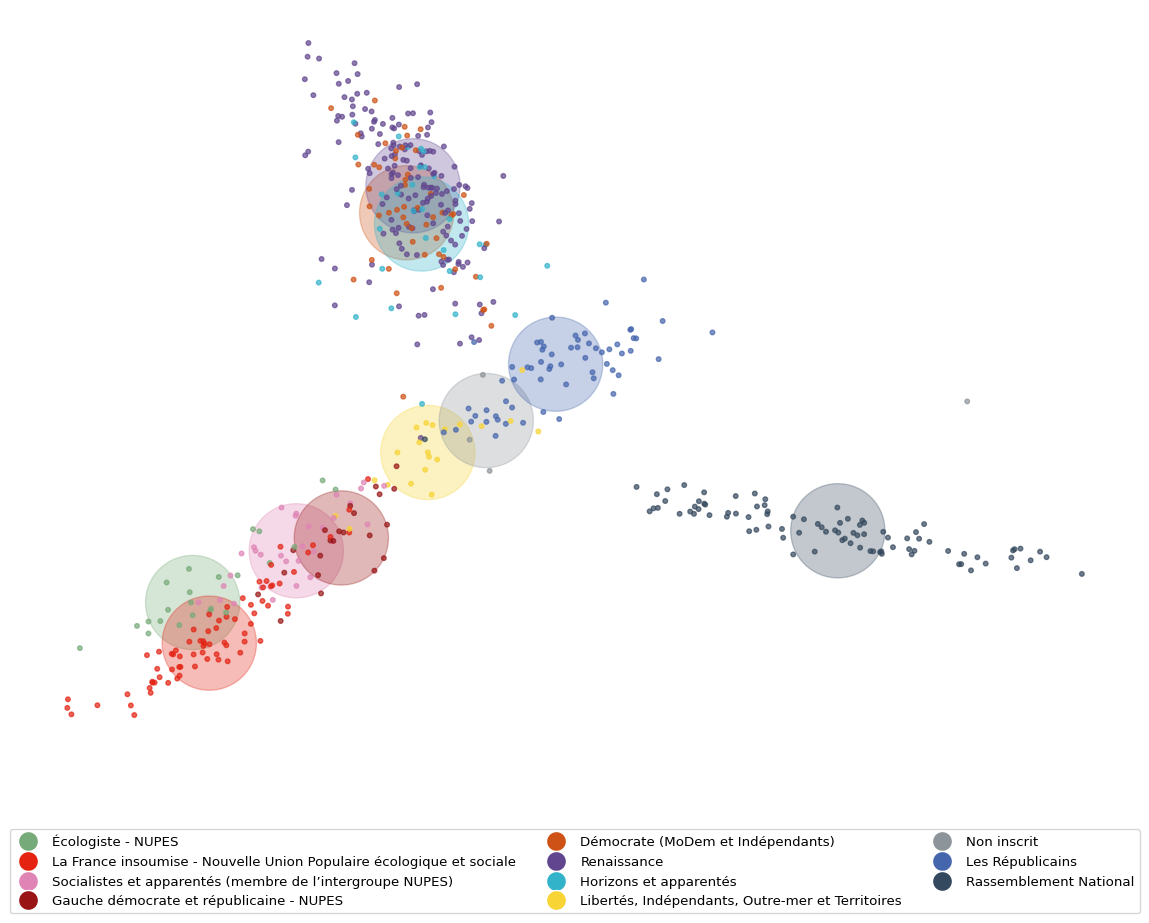
C’est une visualisation surtout illustrative et exploratoire au contraire d’avoir une valeur explicative. Ainsi, le vide autour des députés RN ne permet pas d’inférer grand-chose sur le cordon sanitaire, mais par contre on peut se poser des questions sur l’absence d’une droite d’opposition.
la recette
les ustensiles
Pour cette petite recette, nous aurons besoin de trois ustensiles de cuisine assez classiques :
- pandas pour la manipulation des données
- matplotlib pour la visualisation
- et enfin scikit-learn pour l’analyse en composantes principales
les ingrédients
Les données dont on a besoin sont essentiellement les votes des députés. Elles proviennent du site open data de l’Assemblée Nationale. Initialement au format XML, et un export au format JSON assez dégueux, ici, nous utiliserons une version légèrement retraitée dont le processus est consultable ici.
vectoriser les députés
Chaque député vote “pour”, “contre” ou “s’abstient”, c’est sa position, a un nombre fini de scrutins. Nous allons nous servir de cette information pour construire un vecteur pour chaque député. Chaque colonne correspond donc à un scrutin dont la valeur est encodée numériquement de la façon suivante :
1pour un vote “pour”-1pour un vote “contre”0pour un vote “abstention”
À noter que cela pourrait être n’importe quelle autre séquence de chiffre, mais ainsi on peut faire quelques calculs.
Par souci de cohérence, nous allons stocker ces vecteurs dans une variable \(X\) comme l’idée est d’avoir une fonction de la forme \(y = f(X)\) permettant de situer les députées en fonction de leur vote. Le machine learning permet de trouver les paramètres de cette fonction \(f\).
Pour passer d’un dataframe au format long à une matrice, nous allons utiliser la bonne vieille fonction pivot_table de pandas.
X = (
votes
.assign(
position = lambda df: df.position.replace({'contre': -1, 'pour': 1, 'abstention': 0 })
)
.pivot_table(
index='acteurRef',
columns='scrutin',
values='position'
)
.fillna(0)
)
X| scrutin | VTANR5L16V1 | VTANR5L16V10 | VTANR5L16V100 | VTANR5L16V1000 | VTANR5L16V1001 | VTANR5L16V1002 | VTANR5L16V1003 | VTANR5L16V1004 | VTANR5L16V1005 | VTANR5L16V1006 | ... | VTANR5L16V990 | VTANR5L16V991 | VTANR5L16V992 | VTANR5L16V993 | VTANR5L16V994 | VTANR5L16V995 | VTANR5L16V996 | VTANR5L16V997 | VTANR5L16V998 | VTANR5L16V999 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acteurRef | |||||||||||||||||||||
| PA1008 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | ... | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| PA1206 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PA1327 | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | ... | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PA1567 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PA1592 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| PA805166 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 |
| PA817203 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 |
| PA817211 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| PA822617 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PA942 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | -1.0 | ... | 0.0 | -1.0 | -1.0 | 0.0 | -1.0 | 0.0 | -1.0 | -1.0 | -1.0 | 0.0 |
581 rows × 1858 columns
On se retrouve bien avec une matrice dont les dimensions correspondent au nombre de députés ayant votés en lignes et au nombre de scrutins en colonnes.
Une somme sur les lignes (X.sum(axis=1)) nous donne si un député est plutôt pour ou contre. Pas très utile en soit mais peut être intéressant car il suffit de sélectionne les scrutins en sélection les colonnes avec X.[].
Une somme sur les colonnes (X.sum()) nous donne le résultat des scrutins.
Il est certainement possible de faire la même chose avec scikit-learn mais pourquoi s’embêter quand cela fonctionne et que c’est relativement simple.
réduire à deux dimensions avec une PCA
Une Analyse en Composantes Principales (PCA) est une méthode de réduction de dimension. L’idée est de trouver les plans qui expliquent le mieux la variance des données. Comme une sorte de régression linéaire mais avec beaucoup de variables en entrée et un peu moins en sortie.
Avec la méthode PCA de scikit-learn, c’est relativement simple. Il suffit d’entrainer le modèle sur les données \(X\) et de l’appliquer à ces mêmes données \(X_r = f(X)\) avec la méthode fit_transform qui fait ce qu’elle dit.
array([[-15.75063639, -6.35683458],
[ -6.43963309, 1.39136881],
[ 4.60791914, 3.62369401],
...,
[-13.22659138, -6.41688026],
[ -4.38482652, -1.1218591 ],
[ 0.83122716, 2.55143613]])On se retrouve avec une matrice de deux colonnes correspondant aux deux dimensions. C’est ce qu’on a demandé.
Il faut maintenant recoller les morceaux avec un peu de pandas pour avoir un tableau avec les députés, leur position et leur groupe parlementaire. Pour cela rien de plus quotidien qu’un petit join pour se détendre.
mapping = (
pd
.DataFrame(X_r, columns=["axe 1", "axe 2"])
.join(
X.reset_index()
.join(votes.drop_duplicates(subset='acteurRef').set_index('acteurRef'), on='acteurRef')
.join(organes.set_index('uid'), on='organe')
)
.set_index('acteurRef')
)
mapping| axe 1 | axe 2 | VTANR5L16V1 | VTANR5L16V10 | VTANR5L16V100 | VTANR5L16V1000 | VTANR5L16V1001 | VTANR5L16V1002 | VTANR5L16V1003 | VTANR5L16V1004 | ... | regime | legislature | regimeJuridique | siteInternet | nombreReunionsAnnuelles | secretariat | listePays | positionPolitique | preseance | couleurAssociee | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acteurRef | |||||||||||||||||||||
| PA1008 | -15.750636 | -6.356835 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 6.0 | #DF84B5 |
| PA1206 | -6.439633 | 1.391369 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | NaN | 99.0 | #8D949A |
| PA1327 | 4.607919 | 3.623694 | 0.0 | -1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 4.0 | #4565AD |
| PA1567 | -12.969329 | -5.880126 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 6.0 | #DF84B5 |
| PA1592 | 0.488657 | 1.149012 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | NaN | 99.0 | #8D949A |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| PA805166 | 9.002075 | -0.260314 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Minoritaire | 5.0 | #CE5215 |
| PA817203 | 5.749284 | 1.522692 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Majoritaire | 1.0 | #61468F |
| PA817211 | -13.226591 | -6.416880 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 3.0 | #E42313 |
| PA822617 | -4.384827 | -1.121859 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 10.0 | #F8D434 |
| PA942 | 0.831227 | 2.551436 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -1.0 | -1.0 | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 10.0 | #F8D434 |
581 rows × 1888 columns
visualiser les députés
Avant de passer à la visualisation, prenons un petit moment pour préparer de jolis tables qui pourront être utilisé par des publics moins avertis ou pour afficher des données contextuelles dans une visualisation interactive.
Commencons par les députés :
acteurs_pca = (
mapping
[['axe 1','axe 2', 'organe']]
.join(acteurs.set_index('uid'))
.join(organes.set_index('uid')[['libelleAbrev', 'couleurAssociee']], on='organe')
)
acteurs_pca| axe 1 | axe 2 | organe | nom | prenom | civ | libelleAbrev | couleurAssociee | |
|---|---|---|---|---|---|---|---|---|
| acteurRef | ||||||||
| PA1008 | -15.750636 | -6.356835 | PO800496 | David | Alain | M. | SOC | #DF84B5 |
| PA1206 | -6.439633 | 1.391369 | PO793087 | Dupont-Aignan | Nicolas | M. | NI | #8D949A |
| PA1327 | 4.607919 | 3.623694 | PO800508 | Forissier | Nicolas | M. | LR | #4565AD |
| PA1567 | -12.969329 | -5.880126 | PO800496 | Guedj | Jérôme | M. | SOC | #DF84B5 |
| PA1592 | 0.488657 | 1.149012 | PO793087 | Habib | David | M. | NI | #8D949A |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| PA805166 | 9.002075 | -0.260314 | PO800484 | Bergantz | Anne | Mme | DEM | #CE5215 |
| PA817203 | 5.749284 | 1.522692 | PO800538 | Miller | Laure | Mme | RE | #61468F |
| PA817211 | -13.226591 | -6.416880 | PO800490 | Pilato | René | M. | LFI-NUPES | #E42313 |
| PA822617 | -4.384827 | -1.121859 | PO800532 | Froger | Martine | Mme | LIOT | #F8D434 |
| PA942 | 0.831227 | 2.551436 | PO800532 | de Courson | Charles | M. | LIOT | #F8D434 |
581 rows × 8 columns
Puis les groupes parlementaires en calculant la position médiannne avec un groupby et median.
Au passage, on trie les groupes en fonction de l’axe 2 qui correspond à un axe gauche-droite. Cela permet d’afficher un tas de choses automatiquement sans avoir à classer manuellement les groupes.
Code
| axe 1 | axe 2 | @xmlns | @xmlns:xsi | @xsi:type | codeType | libelleEdition | libelleAbrege | libelleAbrev | viMoDe | ... | regime | legislature | regimeJuridique | siteInternet | nombreReunionsAnnuelles | secretariat | listePays | positionPolitique | preseance | couleurAssociee | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| libelle | |||||||||||||||||||||
| Écologiste - NUPES | -15.940413 | -9.220727 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Écologiste - NUPES | Ecolo - NUPES | ECOLO | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 8.0 | #77AA79 |
| La France insoumise - Nouvelle Union Populaire écologique et sociale | -18.870966 | -8.625866 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe La France insoumise - Nouvelle Union... | LFI - NUPES | LFI-NUPES | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 3.0 | #E42313 |
| Socialistes et apparentés (membre de l’intergroupe NUPES) | -12.208452 | -5.517531 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Socialistes et apparentés (membre de... | SOC | SOC | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 6.0 | #DF84B5 |
| Gauche démocrate et républicaine - NUPES | -11.280576 | -3.909381 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe de la Gauche démocrate et républicai... | GDR - NUPES | GDR-NUPES | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 9.0 | #991414 |
| Démocrate (MoDem et Indépendants) | 12.184351 | -1.573154 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Démocrate (MoDem et Indépendants) | Dem | DEM | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Minoritaire | 5.0 | #CE5215 |
| Renaissance | 14.130518 | -1.349316 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Renaissance | RE | RE | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Majoritaire | 1.0 | #61468F |
| Horizons et apparentés | 11.375504 | -1.042384 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Horizons et apparentés | HOR | HOR | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Minoritaire | 7.0 | #32B3CA |
| Libertés, Indépendants, Outre-mer et Territoires | -5.112847 | -0.817343 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Libertés, Indépendants, Outre-mer et... | LIOT | LIOT | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 10.0 | #F8D434 |
| Non inscrit | -2.809973 | 1.270190 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | des députés non inscrits | NI | NI | {'dateDebut': '2022-06-22', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | NaN | 99.0 | #8D949A |
| Les Républicains | 1.258472 | 3.749839 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Les Républicains | LR | LR | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 4.0 | #4565AD |
| Rassemblement National | -10.763626 | 13.831876 | http://schemas.assemblee-nationale.fr/referentiel | http://www.w3.org/2001/XMLSchema-instance | GroupePolitique_type | GP | du groupe Rassemblement National | RN | RN | {'dateDebut': '2022-06-28', 'dateAgrement': No... | ... | 5ème République | 16.0 | NaN | NaN | NaN | {'secretaire01': None, 'secretaire02': None} | NaN | Opposition | 2.0 | #35495E |
11 rows × 22 columns
Voilà tout est prêt pour la touche finale et laisser matplotlib faire sa magie. Rien de spécial au niveau de la visualisation, c’est la fonction df.plot.scatter qui fait tout le travail. On cache les axes, par préférence personelle comme les valeurs n’ont pas une grande importance, et on ajoute une légende avec les groupes parlementaires.
fig, ax = plt.subplots()
(
axe
.join(organes.set_index('uid'))
.plot
.scatter(
x="axe 2",
y="axe 1",
c="couleurAssociee",
alpha=0.3,
s=5000,
ax=ax,
)
)
(
mapping
.plot
.scatter(
x="axe 2",
y="axe 1",
s=12,
alpha= 0.7,
c="couleurAssociee",
figsize=(15,10),
ax=ax
)
)
plt.legend(
handles=[
plt.Line2D([0], [0], marker='o', color='w', label=org['libelle'], markerfacecolor=org['couleurAssociee'], markersize=15)
for org in axe.join(organes.set_index('uid')).to_records()
],
loc='upper center',
bbox_to_anchor=(0.5, -0.1),
ncol=3
)
ax.axis('off')
plt.savefig('graphics/acteurs_pca_scrutins.png', bbox_inches='tight')
plt.show()
À partir de là, il suffit de sauvegarder les données ou de les injecter pour l’intégrer au système de visualisation souhaité. Pour l’article de Mediapart, c’est du datawrapper branché à un tableur en ligne.