visualiser les données d’alerte propluvia
Dans ce snack, nous allons regarder comment :
- préparer des données qui ne sont pas d’une qualité vertigineuse
- produire un graphique exploratoire
Le but est de voir comment aller au plus simple de la donnée jusqu’à la visualisation.
ingrédients
On commence par importer pandas. Rien de bien surprenant jusque là.
On importe les données légèrement brute de propluvia tout en préparant le typage des colonnes qui nous intéressent en les transformant en date ou en catégorie.
propluvia = (
pd
.read_csv('https://raw.githubusercontent.com/taniki/propluvia/main/propluvia.csv')
.assign(
Date_debut = lambda d: pd.to_datetime(d.Date_debut, errors='coerce'),
Date_fin = lambda d: pd.to_datetime(d.Date_fin, errors='coerce'),
NIVEAU= lambda d: d.NIVEAU.astype('category'),
Region= lambda d: d.Region.astype('category'),
Departement= lambda d: d.Departement.astype('category'),
)
.drop_duplicates()
)
propluvia| Code_ZA | Libelle_ZA | NIVEAU | Date_debut | Date_fin | Duree | Surface | AC_Concerne | Numero_AR | Region | Bassin | Departement | Type_de_zone | Durée | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11_77_02 | Nappe Champigny Est | Crise renforcée | 2010-05-01 | 2011-02-28 | 303.0 | 550.51 | NaN | 2010/DDEA/SEPR/195 | Île-de-France | SEINE-NORMANDIE | Seine-et-Marne | Souterraine | NaN |
| 1 | 11_77_03 | Nappe Champigny Ouest | Crise renforcée | 2010-05-01 | 2011-02-28 | 303.0 | 1718.08 | NaN | 2010/DDEA/SEPR/195 | Île-de-France | SEINE-NORMANDIE | Seine-et-Marne | Souterraine | NaN |
| 2 | 11_91_01 | Bassin de l'Yerres | Absence de restriction | 2010-05-05 | 2011-03-01 | 300.0 | 47.49 | NaN | 2010-DDEA?SE?132 | Île-de-France | SEINE-NORMANDIE | Essonne | Superficielle | NaN |
| 3 | 11_91_01 | Nappe Champigny Ouest | Crise renforcée | 2010-05-05 | 2011-03-01 | 300.0 | 76.94 | NaN | 2010-DDEA?SE?132 | Île-de-France | SEINE-NORMANDIE | Essonne | Souterraine | NaN |
| 4 | 11_91_02 | Bassin de l'Ecole | Absence de restriction | 2010-05-05 | 2011-03-01 | 300.0 | 117.62 | NaN | 2010-DDEA?SE?132 | Île-de-France | SEINE-NORMANDIE | Essonne | Superficielle | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 42964 | MP 14 | Nappe des Autises | Alerte | 2022-05-09 | 2022-05-15 | 6.0 | 260.97 | NaN | AP-22-DDTM85-303 | Pays de la Loire | LOIRE-BRETAGNE | Vendée | Souterraine | NaN |
| 42965 | MP 14 | Nappe des Autises | Alerte | 2022-06-17 | 2022-07-01 | 14.0 | 260.97 | NaN | 22-DDTM85-409 | Pays de la Loire | LOIRE-BRETAGNE | Vendée | Souterraine | NaN |
| 42966 | MP 14 | Nappe des Autises | Alerte | 2022-05-20 | 2022-06-07 | 18.0 | 260.97 | NaN | AP-22-DDTM85-336 | Pays de la Loire | LOIRE-BRETAGNE | Vendée | Souterraine | NaN |
| 42967 | MP 14 | Nappe des Autises | Vigilance | 2022-07-08 | 2022-07-22 | 14.0 | 260.97 | NaN | 22-DDTM85-452 | Pays de la Loire | LOIRE-BRETAGNE | Vendée | Souterraine | NaN |
| 42968 | MP 14 | Nappe des Autises | Vigilance | 2022-07-22 | 2022-10-31 | 101.0 | 260.97 | NaN | 22-DDTM85-504 | Pays de la Loire | LOIRE-BRETAGNE | Vendée | Souterraine | NaN |
42857 rows × 14 columns
niveaux d’alerte
On goute ensuite aux données. Ici, je regarde le nombre d’arrêté par niveau d’alerte. Le Serie.to_frame() est surtout esthétique, Serie.value_counts() renvoyant ici une série qui serait représenté sous forme de texte et non de tableau sans cela.
| NIVEAU | |
|---|---|
| Alerte | 10854 |
| Vigilance | 10161 |
| Crise | 10088 |
| Alerte renforcée | 9504 |
| Crise renforcée | 851 |
| Arrêt des prélèvements non prioritaires | 593 |
| Crise modérée | 550 |
| Absence de restriction | 149 |
| Modification du régime hydraulique | 28 |
Par soucis de concision, on ne va garder que les 4 principaux niveaux.
évolution de la surface des niveaux d’alerte
Afin de décomposer mon code, je prépare une petite fonction qui me donne la surface et le nombre d’arrêté par niveau d’alerte pour une date donnée.
def agg_day(date):
return (
propluvia
[(propluvia.Date_debut <= date) * (propluvia.Date_fin >= date)]
.groupby('NIVEAU')
.agg({
'Surface': 'sum',
'Numero_AR': 'count'
})
.reset_index()
.assign(
date = date,
)
#.drop(columns=propluvia.columns)
)
agg_day('2022-06-15')| NIVEAU | Surface | Numero_AR | date | |
|---|---|---|---|---|
| 0 | Absence de restriction | 0.00 | 0 | 2022-06-15 |
| 1 | Alerte | 87259.51 | 199 | 2022-06-15 |
| 2 | Alerte renforcée | 24435.77 | 73 | 2022-06-15 |
| 3 | Arrêt des prélèvements non prioritaires | 0.00 | 0 | 2022-06-15 |
| 4 | Crise | 6779.20 | 38 | 2022-06-15 |
| 5 | Crise modérée | 0.00 | 0 | 2022-06-15 |
| 6 | Crise renforcée | 0.00 | 0 | 2022-06-15 |
| 7 | Modification du régime hydraulique | 0.00 | 0 | 2022-06-15 |
| 8 | Vigilance | 241842.46 | 414 | 2022-06-15 |
La sélection est faite avec [] par force d’habitude mais pour des soucis de lisibilité, il est souvent préférable d’utiliser DataFrame.query()
Pour aboutir à la visualisation, il y a deux étapes importantes :
- la transformation en table de pivot afin que chaque ligne du graphique corresponde à une colonne. Ici comme, on cherche à avoir une ligne par niveau d’alerte.
- l’utilisation de
DataFrame.plot.line()afin de séparer chaque niveau d’alerte avec le paramètresubplotset la normalisation de l’axe des ordonnées avecsharey.
import matplotlib.pyplot as plt
(
pd
.concat([ agg_day(date) for date in pd.date_range(propluvia.Date_debut.min(),propluvia.Date_fin.max())])
.query('NIVEAU.isin(@niveaux)')
.pivot_table(
index='date',
columns='NIVEAU',
values='Surface'
)
.plot
.line(
sharey=True,
subplots=True,
figsize=(15,len(niveaux)*4),
ylabel='surface (km2)',
)
)
plt.savefig('graphics/propluvia-niveaux.png', facecolor='white', transparent=False)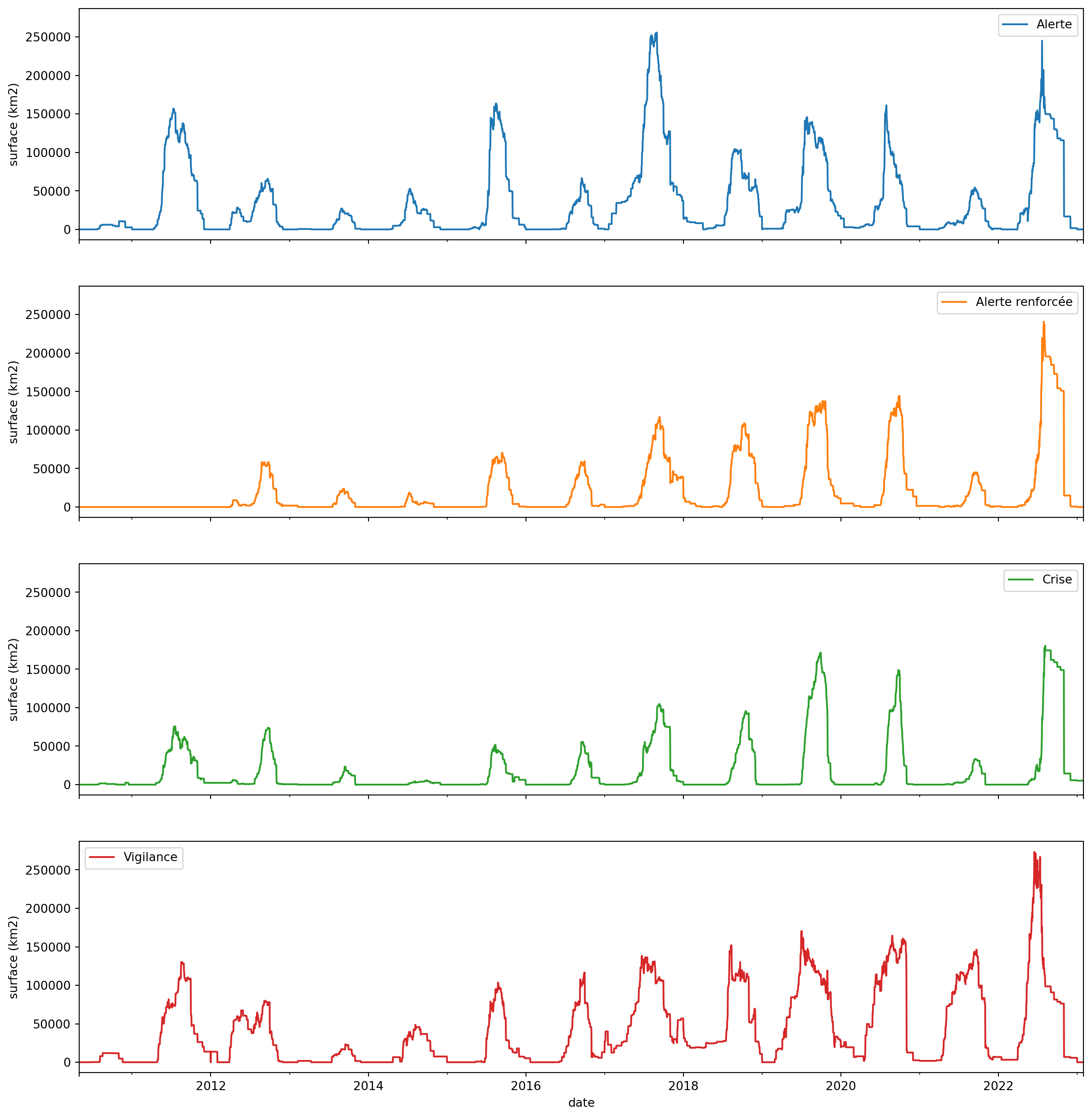
(
propluvia
.query('NIVEAU.isin(@niveaux)')
.pivot_table(
index='Region',
columns='NIVEAU',
values='Surface',
aggfunc='sum'
)
[niveaux]
)| NIVEAU | Alerte | Vigilance | Crise | Alerte renforcée |
|---|---|---|---|---|
| Region | ||||
| Auvergne-Rhône-Alpes | 876865.23 | 1490289.19 | 205485.61 | 510990.78 |
| Bourgogne-Franche-Comté | 541889.09 | 304067.78 | 284922.00 | 302802.50 |
| Bretagne | 291416.45 | 293329.83 | 20642.11 | 54078.45 |
| Centre-Val de Loire | 372786.63 | 175472.81 | 515529.67 | 340807.71 |
| Corse | 43961.59 | 125953.05 | 0.00 | 23081.19 |
| Grand-Est | 439493.13 | 127040.61 | 8631.22 | 273625.34 |
| Hauts-de-France | 150273.87 | 284564.16 | 5690.04 | 32149.72 |
| Normandie | 97692.49 | 267389.62 | 15486.78 | 30342.10 |
| Nouvelle-Aquitaine | 918336.50 | 451461.35 | 920951.43 | 840590.52 |
| Occitanie | 671419.42 | 798545.95 | 453210.48 | 517558.06 |
| Pays de la Loire | 529736.71 | 948949.48 | 506058.29 | 534155.64 |
| Provence-Alpes-Côte d'Azur | 172623.75 | 446274.37 | 23164.92 | 109890.72 |
| Île-de-France | 63412.13 | 82448.24 | 21813.49 | 24460.52 |
après
Voilà, je suis allé au plus court et il y a possibilité d’aller plus loin :
- ordonner les niveaux d’alerte : Categorical data
- améliorer le graphique de synthèse : pandas.DataFrame.plot